Cyclic Nature of Time- Kaggle Submission
- With this notebook we continue our analysis of
bikesharedataset. - In this part we will do machine learning steps in order to predict the bike rentals for the given Kaggle test set and submit it to the Kaggle
- In the previous post, we prepared the dataset partially
- We created new columns and dropped the outliers regarding to the
"count"column - Now we start by loading the dataset and continue to prepare it before applying machine learning algorithms
Outline:¶
- About Time Data
- Trigonometric functions for cyclic time data transformation
- Data Split
- TimeSeriesSplit for the cross validation
- Sklearn Pipeline
- Interpratation of RSMLE metric
- Creating a custom scoring function
- Kaggle submission
# Import the necessary modules
import pandas as pd
import matplotlib.pyplot as plt
import seaborn as sns
import numpy as np
from sklearn.preprocessing import StandardScaler
from sklearn.model_selection import TimeSeriesSplit
from sklearn.linear_model import LinearRegression
from sklearn.model_selection import train_test_split
from sklearn.model_selection import cross_val_score
from sklearn.metrics import r2_score
from sklearn.metrics import mean_squared_error
from sklearn.metrics import make_scorer
from sklearn.pipeline import Pipeline
import warnings
warnings.filterwarnings("ignore")
%matplotlib inline
sns.set()
Let's remind our dataset¶
Kaggle terms for the dataset:¶
-
The training set is comprised of the first
19 daysof each month, while the test set comprised of the days from20thto the end of the month for each month. -
Predict the
total count of bikes rented during each hourcovered by the test set, using onlyinformation available prior to the rental period.
Here is the Kaggle link for the dataset
# Read the bike_data_inliers
bike_data=pd.read_csv("bike_data_inliers.csv", parse_dates=["datetime"], index_col="datetime")
bike_data.head(3)
## Filter out the casual and registered columns and
## high correlated columns "season" (correlated with "month") and "atemp" (correlated with "temp") should be omitted
## Also in the previous post we noticed that the data record in the "weather" column is not relaible
## We will also drop it
bike_data= bike_data.drop(["casual", "registered", "season", "atemp", "weather"], axis=1)
bike_data.head(3)
About Time Data¶
- Since our data is a timeseries, i.e data recorded with a time dimension, we need to take into account the timeseries practices.
- Firstly, we need to be aware of the
cyclicnature of our time data
- As we walked through the time frame charts in the previous post, we saw that
monthandhourvariables are very predictive over the number of bike rentals.
- This is very resaonable as we might expect that the bike usage and rentals during
Januaryis less thanMaydue to the weather conditions and rentals at3amin the morning is less than at14h, during the day.
-
So we should use the
"month"and"hour"data as features for our models. However, we have a problem of how to utilize these features. -
We need to keep them numeric for the machine learning algorithms but if we use them without any transformation, it would not be so smart practice.
To make it clearer here is a question:
- Which one would you expect is more similar to the bike rentals in
January: rentals inDecemberor rentals inMay?
-
Regarding the seasonal affects we can tell that number of bike rentals in
Decemberis more similar to rentals inJanuary, however we representDecemberwith number12andMaywith number5. -
This is a wrong representation of the time features especially for the algorithms that use distance or the algorithms like linear regression.
As an example let's assume our model is $$ bikerentals= 15+ 2*hour $$
At 0h the number of estimated rentals = 15
At 23h the number of estimated rentals= 61
Even though there is only 1 hour difference between 0h-23h with this represantation the difference is the largest
- Because of the cyclic nature of the months and hours we need to find a way of representing these features such that
- the
12thmonth should be closer to1stmonth than5thmonth or -
23thhour should be closer to1sthour than7th hour.
- the
Representation of Cyclic Time Features¶
-
We map each cyclical variable onto a circle such that the
lowest valuefor that variable appears right next to thelargest value. -
We represent each variable with two components: x axis value and y axis value
-
We compute the
xandycomponents of that point usingsinandcosfunctions.
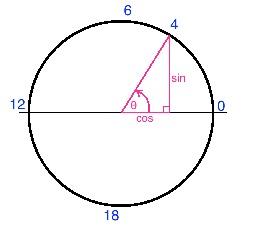
- When we perform this transformation for the
"month"variable, we also shift the values down by one such that it extends from0 to 11, for convenience
NOTE: Instead of represanting the time features with trigonometric functions we can also use dummy variables. Here we will go with the trigonometric functions
# Create the sin and cos components of hour, month and weekday columns
bike_data['hour_sin'] = np.sin(bike_data.index.hour*(2.*np.pi/24))
bike_data['hour_cos'] = np.cos(bike_data.index.hour*(2.*np.pi/24))
bike_data['month_sin'] = np.sin((bike_data.index.month-1)*(2.*np.pi/12))
bike_data['month_cos'] = np.cos((bike_data.index.month-1)*(2.*np.pi/12))
bike_data["weekday_cos"]= np.cos((bike_data.index.weekday)*(2.*np.pi/7))
bike_data['weekday_sin'] = np.sin((bike_data.index.weekday)*(2.*np.pi/7))
# Now we can drop the columns "month", "weekday" and "hour"
bike_data=bike_data.drop(["month", "weekday", "hour"], axis=1)
Split the data¶
-
Even though there is a given test set (without target variable) for Kaggle submission we will analyse the data as an independent project and follow our data splitting principles
-
At the end we will use the Kaggle test set for submission
-
So, after instantiating a model we will use cross validation for evaluating model performance and hyperparameter tuning but we still we need to keep an hold-out set for our final evaluation.
-
Since this is a timeseries dataset we must respect to the temporal order of the data. Thus, we must use only the past data to predict the future data.
-
So we can take the last %5 as our hold-out data. (In the Kaggle competition the test set is the last 10 days of the months)
-
We need to split the data before doing transformation (incase we do) because test data points represent real-world data.
- Transformation of the variables use information from the dataset like mean and standard deviation
-
If we transform the data before splitting we take information like mean and variance of the whole dataset thus we will be introducing future information to the training data.
-
Therefore, we should perform transformation over the training data. Then perform the same transformation on testing data as well, but this time using the parameters (like mean and variance) of the training data.
# Find the starting indice of the last five percent
last_five_percent_ind= int(len(bike_data)* 0.95)
last_five_percent_ind
# Create the hold-out dataset
hold_out_df=bike_data.reset_index().iloc[last_five_percent_ind: ,:]
print("The shape of the hold-out dataset:", hold_out_df.shape)
hold_out_df.head(3)
We will do training and cross validation on the rest of the data. Lets create it
data= bike_data.reset_index().iloc[:last_five_percent_ind, :]
data.tail(3)
Features and Target Variable¶
Having splitted the hold-out dataset, now time to create the features (X) and the target (y) datasets and fit a Linear Regression model
# Target data
y=data["count"]
# Features data
X=data.drop(["datetime", "count"], axis=1)
X.head(3)
Notes about Cross Validation of Timeseries Data¶
Here is the the notes from sklearn official page :
Time series data is characterised by the correlation between observations that are near in time (autocorrelation).
However, classical cross-validation techniques such as KFold and ShuffleSplit
- assume the samples are independent and identically distributed, and
- would result in unreasonable correlation between training and testing instances (yielding poor estimates of generalisation error) on time series data.
Therefore, it is very important to evaluate our model for time series data on the “future” observations least like those that are used to train the model.
Time Series Split¶
TimeSeriesSplit is a variation of k-fold which
- returns first
kfolds as train set and - the
k+1 thfold as test set.
- We should not shuffle our data when making predictions with timeseries.
- Unlike standard cross-validation methods, successive training sets are supersets of those that come before them.
- Also, it adds all surplus data to the first training partition, which is always used to train the model.
Sklearn Pipeline¶
Whenever possible, using Sklearn Pipeline object is always a smart practice because they
- are powerfull tools to standardise our operations,
- create an easy-to-understand workflow with clear order of steps,
- are reproducable
We will create a pipeline with StandartScaler and LinearRegression objects
# Instantiate the pipeline with the StandardScaler and LinearRegression
pipeline=Pipeline(steps= [("scaler", StandardScaler()),
("linreg", LinearRegression())])
Cross validation scores¶
Let's use the cross_val_score from sklearn.metrics to get the scores of each split
# Split the timeseries data
split = TimeSeriesSplit(n_splits=5)
# Fit and score the model with cross-validation
scores = cross_val_score(pipeline, X, y, cv=split)
print("R^2 scores of each split:", scores)
Visualizing CV Splits for Timeseries: "TimeSeriesSplit"¶
Visualize the splits of cross validation with TimeSeriesSplit object
# Initialize the cross-validation iterator with 10 splits
cv = TimeSeriesSplit(n_splits=10)
fig, ax = plt.subplots(figsize=(10, 5))
# Loop over the cross validation splits
# cv.split() method creates train and test arrays for each split
for idx, (train, test) in enumerate(cv.split(X, y)):
# Plot training and test indices
indeces1 = ax.scatter(train, [idx] * len(train), c=[plt.cm.coolwarm(.1)], marker='_', lw=8)
indeces2 = ax.scatter(test, [idx] * len(test), c=[plt.cm.coolwarm(.9)], marker='_', lw=8)
ax.set(ylim=[10, -1], title='TimeSeriesSplit behavior', xlabel='Data index', ylabel='CV iterates')
ax.legend([indeces1, indeces2], ['Training', 'Validation'])

Scoring Metric: "RMSLE"¶
Lets try to understand the metric which we will use for the Kaggle evaluation. Here is the screen shot from the Kaggle evaluation page.

So we need to take into account the metric Root Mean Squared Log Error(RMSLE) for this project. For the interpretation of RMSLE take a look to this page
RSMLE Calculator Function¶
# Define the RMSLE function for error calculation: rmsle_calculator
# Using the vectorized numpy functions instead of loops always better for computation
def rmsle_calculator(predicted, actual):
assert len(predicted) == len(actual)
return np.sqrt(
np.mean(
np.power(np.log1p(predicted)-np.log1p(actual), 2)))
Custom Scoring Function¶
-
Having defined our function for the RMSLE calculation, now we should define a scoring function in order to use as a scoring parameter for
model_selection.cross_val_score -
We need this parameter for model-evaluation tools which rely on a scoring strategy when using cross-validation internally (such as
model_selection.cross_val_scoreandmodel_selection.GridSearchCV)
We will use make_scorer function of Sklearn to generate a callable object (from our rsmle_calculator function) for scoring.
When defining a custom scorer via sklearn.metrics.make_scorer, the convention is that
- custom functions ending in
_scorereturn a value to maximize and - for scorers ending in
_lossor_error, a value is returned to be minimized. - We can use this functionality by setting the
greater_is_betterparameter insidemake_scorer. - This parameter would be
-
Truefor scorers where higher values are better, and -
Falsefor scorers where lower values are better. (this will be our choise since the lower RSMLE values are better)
-
NOTE:
- If a loss, the output of the python function, is negated by the scorer object, conforming to the cross validation convention; that scorers return higher values for better models i.e
- when
greater_is_betterisFalse, the scorer object will sign-flip the outcome of thescore_func.
# Make a custom scorer
# rmsle_error will negate the return value of rmsle_calculator,
rmsle_error = make_scorer(rmsle_calculator, greater_is_better=False)
# Fit and score the model with cross-validation
scores = cross_val_score(pipeline, X, y, cv=split, scoring=rmsle_error)
scores
As explained the scores are negative due to the Sklearn customs. We can multiply the results by -1 for our interpretation
print("The cross validation scores:", scores*-1)
Hold-out Data Prediction Scores¶
# Hold-out target data
y_hold=hold_out_df["count"]
# Hold-out features data
X_hold=hold_out_df.drop(["datetime", "count"], axis=1)
# Fit the pipeline to train data
pipeline.fit(X, y)
# Generate predictions for hold-out data
predictions_hold = pipeline.predict(X_hold)
# R^2 score
score = r2_score(y_hold, predictions_hold)
print("R^2 score of hold-out:", score)
print("Root mean squared error of hold-out:", np.sqrt(mean_squared_error(y_hold, predictions_hold)))
print ("RMSLE value for linear regression of hold-out: ", rmsle_calculator(y_hold , abs(predictions_hold)))
Kaggle submission¶
Lets predict the given Kaggle test set and submit the predictions to Kaggle to get our score.
First it would be better if we combine our X and X_hold and y and y_hold datasets then train our model with more data in order to let our model learn better before predicting on a new test data i.e Kaggle test dataset which we have not yet uploaded.
# Combine X and X hold: combined_train
combined_X=pd.concat([X, X_hold])
# Combine the y and y hold: combined_test
combined_y =pd.concat([y, y_hold])
# Fit the model to the combined datasets
pipeline.fit(combined_X, combined_y)
# Read the Kaggle test data
kaggle_test=pd.read_csv("bike_kaggle_test.csv", parse_dates=["datetime"], index_col="datetime")
kaggle_test.head(3)
Lets also apply all the steps that we followed for train data to the test data in order to conform the train and test datasets
kaggle_test["month"]=kaggle_test.index.month
kaggle_test["weekday"]=kaggle_test.index.dayofweek
kaggle_test["hour"]=kaggle_test.index.hour
# Create the sin and cos components of hour, month and weekday columns
kaggle_test['hour_sin'] = np.sin(kaggle_test.hour*(2.*np.pi/24))
kaggle_test['hour_cos'] = np.cos(kaggle_test.hour*(2.*np.pi/24))
kaggle_test['month_sin'] = np.sin((kaggle_test.month-1)*(2.*np.pi/12))
kaggle_test['month_cos'] = np.cos((kaggle_test.month-1)*(2.*np.pi/12))
kaggle_test["weekday_cos"]= np.cos((kaggle_test.weekday)*(2.*np.pi/7))
kaggle_test['weekday_sin'] = np.sin((kaggle_test.weekday)*(2.*np.pi/7))
# Drop the wrong represantation of time: month, weekday, hour
# Drop the correlated features: atemp, season
# Drop the weather column (not relaible data records)
X_kaggle_test= kaggle_test.drop(["season", "month", "weekday", "hour", "atemp", "weather"], axis=1)
X_kaggle_test.head(3)
Our Kaggle test dataset is in the same structure with our combined_X dataset. Time to predict and submit!
final_predictions=pipeline.predict(X_kaggle_test)
Having predicted the test targets now we need to create a dataframe complying with Kaggle submission format like shown in the screenshot

kaggle_sub=pd.DataFrame({"datetime":kaggle_test.index, "count":final_predictions}).set_index("datetime")
kaggle_sub["count"]=kaggle_sub["count"].abs()
kaggle_sub.head(3)
# Save the submission dataframe
kaggle_sub.to_csv("kaggle_sub.csv")
Kaggle Submission Score¶
When we fit our model to the Kaggle test set and submited we got the score below. This competition is closed so there is no ranking anymore but to get a bit of idea about our model's performance the mean ranking and the two scores in the ranking that our score fall in between were below.
For the start of our project this is a pretty good score.
- We have just tried Linear Regression so far and also
- we did not used new features except from the time features.
- Later we can work more on this and i think our ranking can get better
Our score:

Mean value benchmark:

The ranking that our score falls in

Wrap Up¶
This was the second part of our analysis on bikeshare dataset
In this notebook we
- continued to prepare our dataset for machine learning
- used the trigonometric function for time data transformation in order to better represent the cyclic nature of time features
- splitted our data set and keep an hould-out test set for final evaluation
- used
TimeSeriesSplititerators for the cross validation of timeseries data. This was important in order to only using past data to evaluate our model on the “future” observations - used Sklearn Pipeline for better workflow
- understood the mechanism and the functionality of the RSMLE metric
- created a custom scoring function which uses RSMLE for the sklearn model evaluation tools
- prepared and predicted the Kaggle testset and made a submission
In the next post we will continue our analysis of bikeshare data with tree-based models and focus on model performance especially with visualization tools
Comments